Introduction
Data, Coding and Reproducibility
AEM 7010 · Doing Applied Economics Research: Practical Skills
2026-04-08
A bit about me
§ Section 1: Introduction
- Prof. Ariel Ortiz-Bobea at Dyson and Brooks Schools. Joined Cornell in 2014.
- Research focus on how people cope with environmental change. Emphasis on how climate change affects the economy, particularly agriculture.
- Research group working on environmental and agricultural issues.

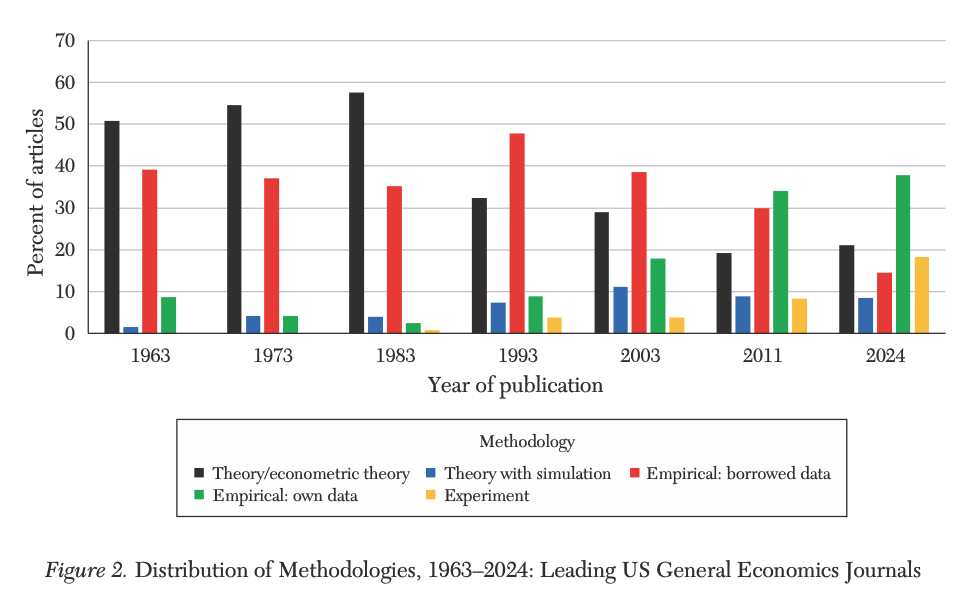
Trend #1: More empirical
§ Trend #1
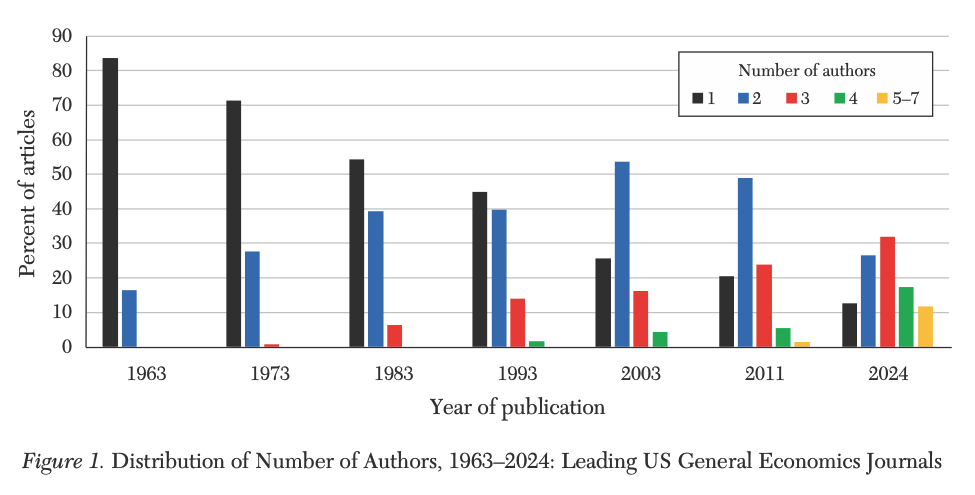
Trend #2: Bigger teams
§ Trend #2
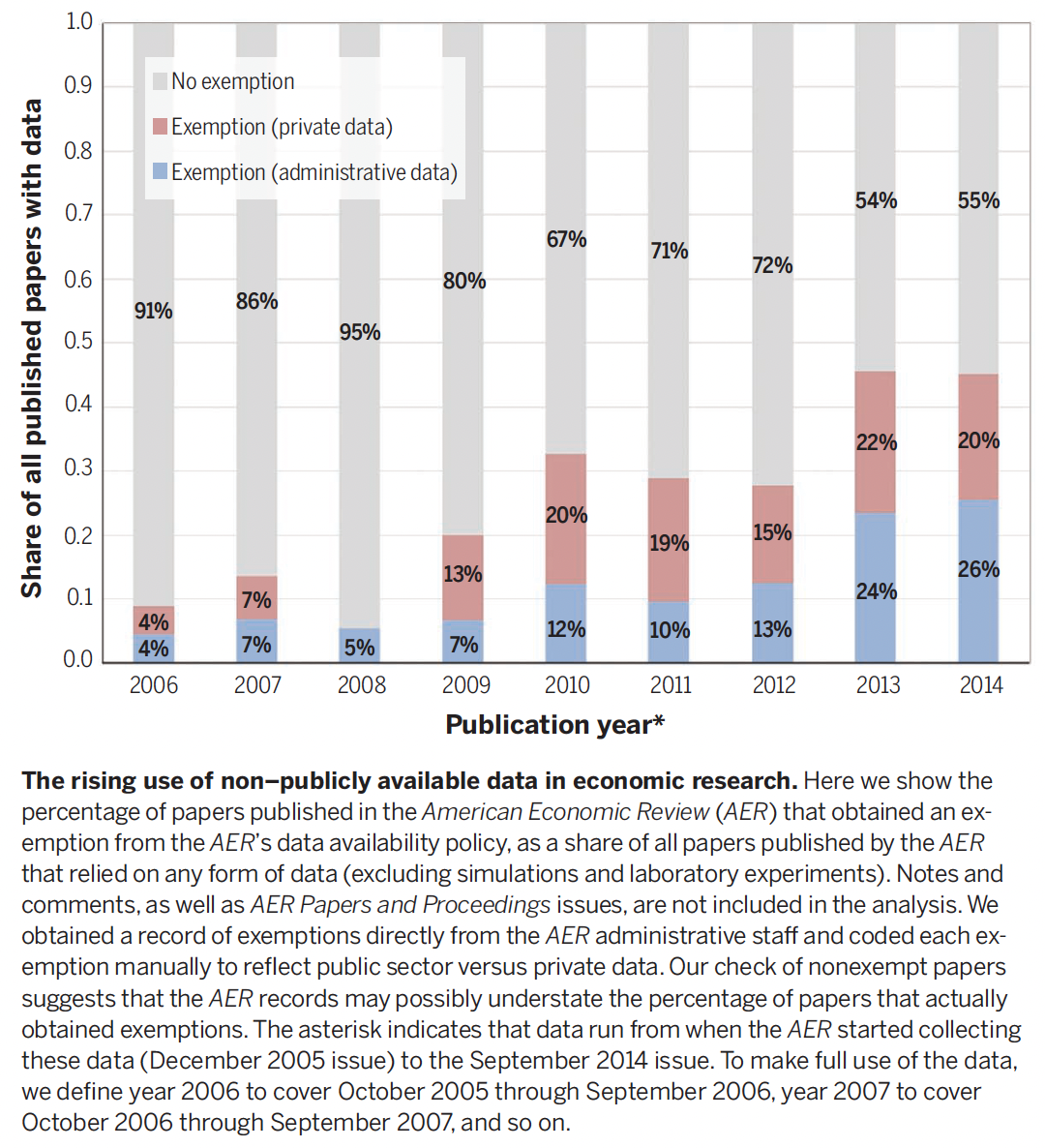
Trend #3: The rise of “complete” restricted and private datasets
§ Trend #3
- e.g. the Social Security Administration, the Internal Revenue Service, and the Centers for Medicare and Medicaid.
- But also private companies collaborating with researchers (Ebay, Uber, etc.).
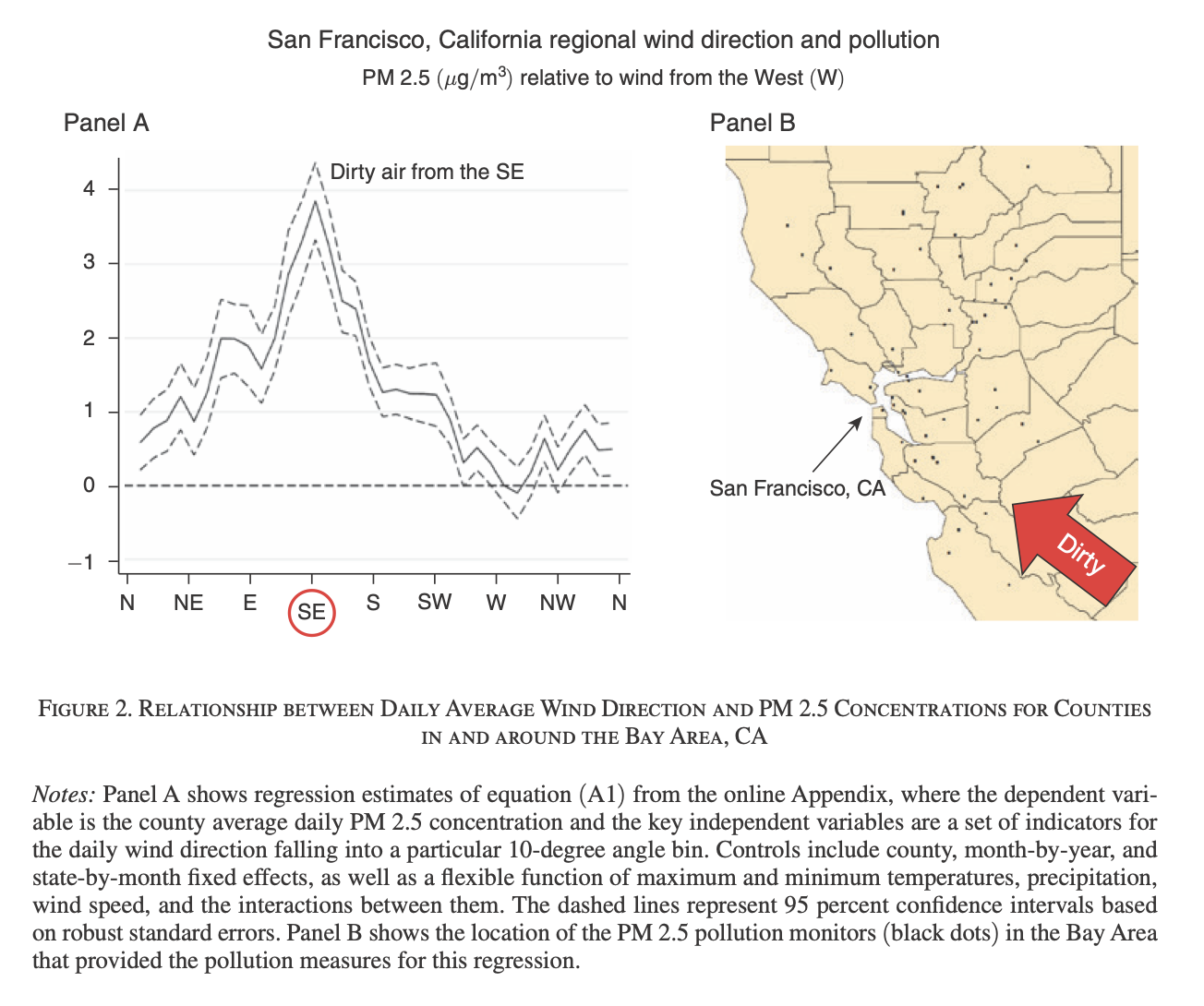
Wind direction as an instrument
§ Trend #5
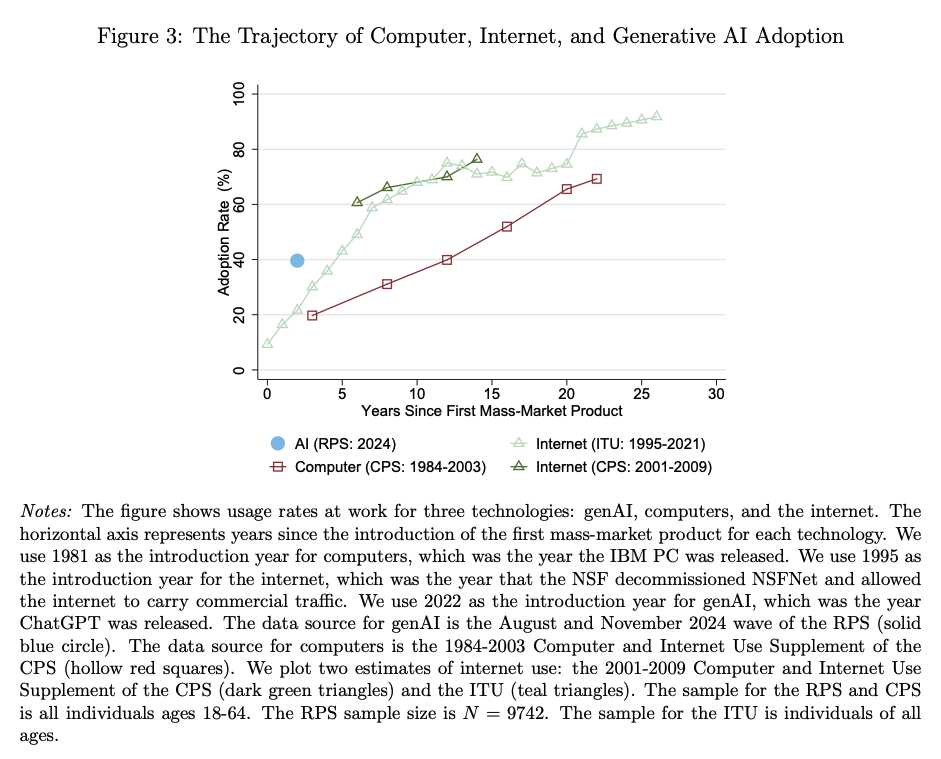
Trend #6: Rapidly rising use of AI tools
§ Trend #6
- ChatGPT launched in November of 2022.
- Profession scrambling to adjust to write policies (for papers, reviewers, etc.).
Next 2 sessions on reproducibility
§ Section 5: Preparing next sessions
- Conducted by Lars Vilhuber, AEA Data Editor and Senior Research Associate in the Economics Department at Cornell.
- Coding assignment:
- Link: https://forms.gle/qB9TFvGs8fGE6dPU9
- Complete by Monday April 13.
- 24 hours to complete.
- Work by yourself, with the language of your choice.
